Метод кластеризации — это задача группирования набора объектов таким образом, чтобы они в одной и той же группе были больше похожи друг на друга, чем на предметы в других отраслях. Это основная задача интеллектуального анализа данных и общая методика статистического разбора, используемая во многих областях, включая машинное обучение, распознавание образов, изображений, поиск информации, сжатие данных и компьютерную графику.
Задача оптимизации
 Вам будет интересно:"Веселый": синонимы к слову, толкование
Вам будет интересно:"Веселый": синонимы к слову, толкование
Сам метод кластеризации — это не один конкретный алгоритм, а общая задача, которую нужно решить. Это может быть достигнуто с помощью различных алгоритмов, которые существенно разнятся в понимании того, что составляет группа и как ее эффективно находить. Использования метода кластеризации для формирования метапредметных включают в себя применение группы с небольшими расстояниями между членами, плотными областями пространства, интервалами или определенными статистическими распределениями. Поэтому кластеризацию можно сформулировать как многоцелевую задачу оптимизации.
Соответствующий метод и настройки параметров (включая такие пункты, как функция расстояния для использования, порог плотности или число ожидаемых кластеров) зависят от индивидуального набора данных и предполагаемого использования результатов. Анализ как таковой является не автоматической задачей, а итеративным процессом обнаружения знаний или интерактивной многоцелевой оптимизации. Такой метод кластеризации включает в себя пробные и неудачные попытки. Часто необходимо изменять предварительную обработку данных и параметры модели, пока результат не достигнет желаемых свойств.
 Вам будет интересно:Уравнение состояния идеального газа. Изопроцессы в газах
Вам будет интересно:Уравнение состояния идеального газа. Изопроцессы в газах
Помимо термина «кластеризация» существует ряд слов с похожими значениями, включая автоматическую классификацию, числовую таксономию, ботриологию и типологический анализ. Тонкие различия часто заключаются в использовании метода кластеризации для формирования метапредметных связей. В то время как при извлечении данных результирующие группы представляют интерес, в автоматической классификации уже дискриминационная сила выполняет данные функции.
Кластерный анализ был основан по многочисленным работам Кребера в 1932 году. И введен в психологию Зубиным в 1938 и Робертом Трионом в 1939 году. И данные труды использовались Кеттелом начиная с 1943 для обозначения признака классификация методов кластеризации в теории.
Термин
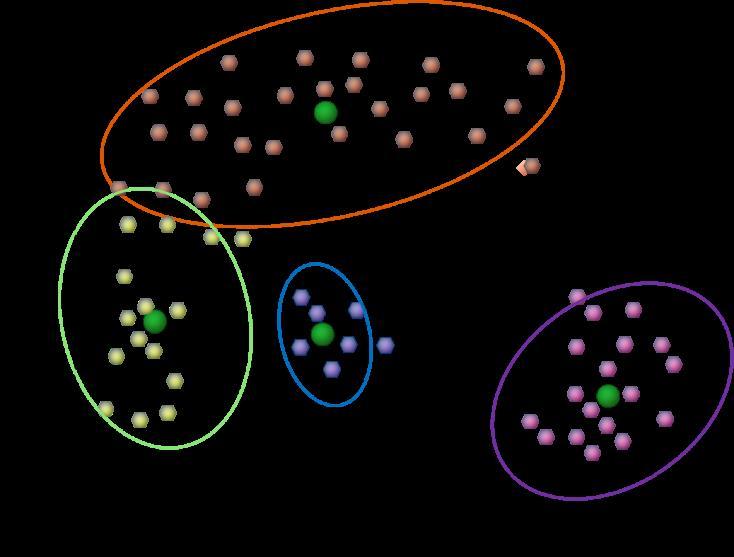
Понятие «кластер» не может быть точно определено. Это является одной из причин, по которой имеется так много методов кластеризации. Существует общий знаменатель: группа объектов данных. Однако всевозможные исследователи используют разные модели. И каждое из этих использований методов кластеризации включает в себя различные данные. Понятия найденного всевозможными алгоритмами существенно различается по его свойствам.
 Вам будет интересно:Вандербильт Консуэло: история герцогини, биография, фото
Вам будет интересно:Вандербильт Консуэло: история герцогини, биография, фото
Использование метода кластеризации является ключом к пониманию отличий между инструкциями. Типичные кластерные модели включают в себя:
- Центроид s. Это, например, когда кластеризация методом к-средних представляет каждый кластер с одним средним вектором.
- Модель связности s. Это уже, например, иерархическая кластеризация, которая строит модели на основе дистанционной связности.
- Модель распределения s. В данном случае кластеры моделируются с использованием метода кластеризации для формирования метапредметных статистических распределений. Таких как многомерное нормальное разделение, которое применимо для алгоритма максимизации ожидания.
- Модель плотности s. Это, например, DBSCAN (алгоритм пространственной кластеризации с присутствием шума) и OPTICS (точки заказа для определения структуры), которые определяют группы как связанные плотные области в пространстве данных.
- Модель подпространства с. В biclustering (также известный как со-кластеризация или два режима) группы моделируются с обоими элементами и с соответствующими атрибутами.
- Модель s. Некоторые алгоритмы не дают уточненную связь для их метода кластеризации для формирования метапредметных результатов и просто обеспечивают группировку информации.
- Модель на основе графа s. Клик, то есть подмножество узлов, такой, что каждые два соединения в реберной части можно рассматривать как прототип формы кластера. Ослабление полного требования известны как квазиклики. Точно такое же название представлено в алгоритме кластеризации HCS.
- Нейронные модели s. Наиболее известной сетью без надзора является самоорганизующаяся карта. И именно эти модели обычно можно охарактеризовать как аналогичные одному или нескольким из вышеуказанных методов кластеризации для формирования метапредметных результатов. Включает он в себя подпространственные системы тогда, когда нейронные сети реализуют необходимую форму анализа главных или независимых компонентов.
Данный термин – это, по сути, комплект таких групп, которые обычно содержат все объекты в наборе методов кластеризации данных. Кроме того, он может указывать отношения кластеров друг к другу, например, иерархию систем, встроенных друг в друга. Группировка может быть разделена на следующие аспекты:
- Жесткий центроидный метод кластеризации. Здесь каждый объект принадлежит группе или находится вне ее.
- Мягкая или нечеткая система. В данном пункте уже каждый объект в определенной степени принадлежит всякому кластеру. Называется он также методом нечеткой кластеризации c-средних.
И также возможны более тонкие различия. Например:
- Строгая секционирующая кластеризация. Здесь каждый объект принадлежит ровно одной группе.
- Строгая секционирующая кластеризация с выбросами. В данном случае, объекты также могут не принадлежать ни к одному кластеру и считаться ненужными.
- Перекрывающаяся кластеризация (также альтернативная, с несколькими представлениями). Здесь объекты могут принадлежать более чем к одному ответвлению. Как правило, с участием твердых кластеров.
- Иерархические методы кластеризации. Объекты, принадлежащие дочерней группе, также принадлежат родительской подсистеме.
- Формирования подпространства. Хотя они и похожи на кластеры с перекрытием, внутри уникально определенной системы взаимные группы не должны загораживаться.
Инструкция
 Вам будет интересно:Вглядитесь внимательно. Не попались ли среди встречных шедшие на вы?
Вам будет интересно:Вглядитесь внимательно. Не попались ли среди встречных шедшие на вы?
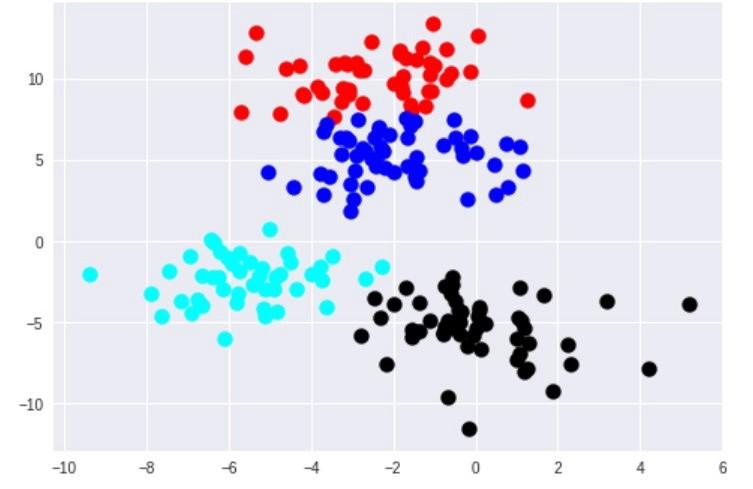
Как указано выше, алгоритмы кластеризации можно классифицировать на основе их кластерной модели. В следующем обзоре будут перечислены только наиболее яркие примеры данных инструкций. Поскольку, возможно, существует более 100 опубликованных алгоритмов, не все предоставляют модели для своих кластеров, и поэтому не могут быть легко классифицированы.
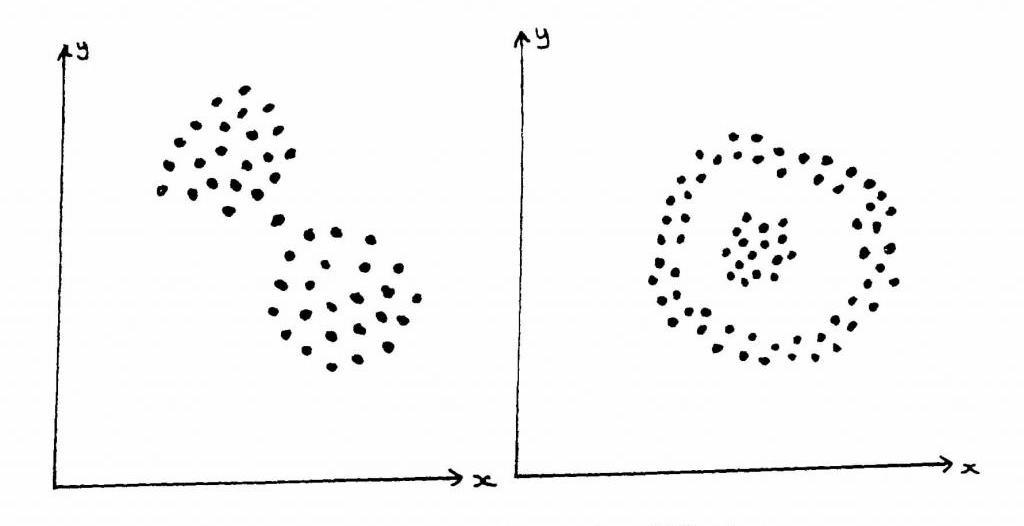
Не существует объективно правильного алгоритма кластеризации. Но, как было отмечено выше, инструкция всегда находится в поле зрения наблюдателя. Наиболее подходящий алгоритм кластеризации для конкретной задачи часто приходится выбирать экспериментально, если только нет математической причины для предпочтения одной модели другой. Следует отметить, что алгоритм, разработанный для единственного типа, обычно не работает с набором данных, который содержит радикально другой субъект. Например, k-means не может найти невыпуклые группы.
Кластеризация на основе соединений
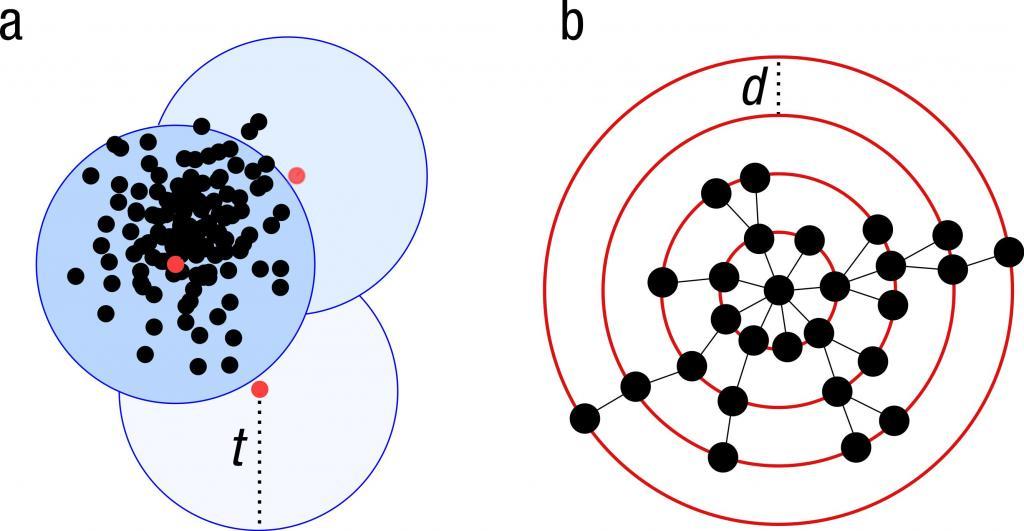
Данное объединение также известно по такому названию, как иерархическая модель. Она основана на типичной идее о том, что объекты в большей степени связаны с соседними частями, чем с теми, которые находятся намного дальше. Эти алгоритмы соединяют предметы, образуя различные кластеры, в зависимости от их расстояния. Группа может быть описана в основном максимальной дистанцией, которая необходима для соединения различных частей кластера. На всевозможных расстояниях будут образовываться другие группы, которые можно представить с помощью дендрограммы. Это объясняет, откуда происходит общее название «иерархическая кластеризация». То есть эти алгоритмы не обеспечивают единого разделения набора данных, а вместо этого предоставляют обширный порядок подчинения. Именно благодаря ему происходит слив друг с другом на определенных расстояниях. В дендрограмме ось Y обозначает дистанцию, на которой кластеры объединяются. А объекты располагаются вдоль прямой X так, что группы не смешиваются.
Кластеризация на основе соединений — это целое семейство методов, которые отличаются способом вычисления расстояний. Помимо обычного выбора функций дистанции пользователю также необходимо определиться с критерием связи. Так как кластер состоит из нескольких объектов, есть множество вариантов для его вычисления. Популярный выбор известен как однорычажная группировка, именно это метод полной связи, который содержит UPGMA или WPGMA (невзвешенный или взвешенный ансамбль пар со средним арифметическим, также известный как кластеризация средней связи). Кроме того, иерархическая система может быть агломерационной (начиная с отдельных элементов и объединяя их в группы) или делительной (начиная с полного набора данных и разбивая его на разделы).
Распределенная кластеризация
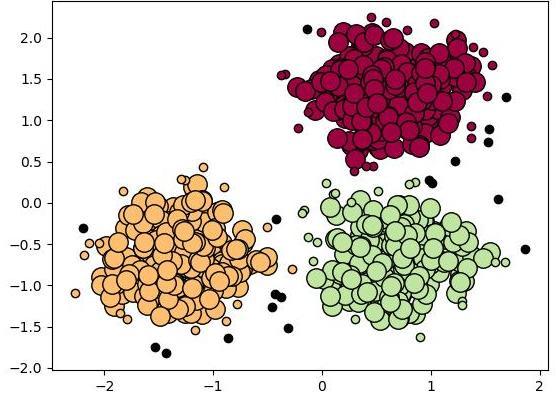
Данные модели наиболее тесно связаны со статистикой, которая основана на разделениях. Кластеры могут быть легко определены как объекты, принадлежащие, скорее всего, к одному и тому же распределению. Удобным свойством этого подхода является то, что он очень похож на способ создания искусственных наборов данных. Путем выборки случайных объектов из распределения.
Хотя теоретическая основа этих методов превосходна, они страдают от одной ключевой проблемы, известной как переоснащение, если только не накладываются ограничения на сложность модели. Более масштабная связь обычно сможет лучше объяснить данные, что затрудняет выбор подходящего способа.
Модель гауссовой смеси
Данный способ использует всевозможные алгоритмы максимизации ожидания. Здесь набор данных обычно моделируется с фиксированным (чтобы избежать переопределения) числом гауссовских распределений, которые инициализируются случайным образом и параметры которых итеративно оптимизируются для лучшего соответствия набора данных. Эта система будет сходиться к локальному оптимуму. Именно поэтому несколько прогонов могут давать разные результаты. Чтобы получить самую жесткую кластеризацию, объекты часто присваиваются гауссовскому распределению, к которому они, скорее всего, принадлежат. А для более мягких групп это не обязательно.
Кластеризация на основе распределения создает сложные модели, которые в конечном счете могут фиксировать корреляцию и зависимость между атрибутами. Однако эти алгоритмы накладывают дополнительное бремя на пользователя. Для многих реальных наборов данных может не быть кратко определенной математической модели (например, если предполагать, что гауссово распределение является довольно сильным допущением).
Кластеризация на основе плотности
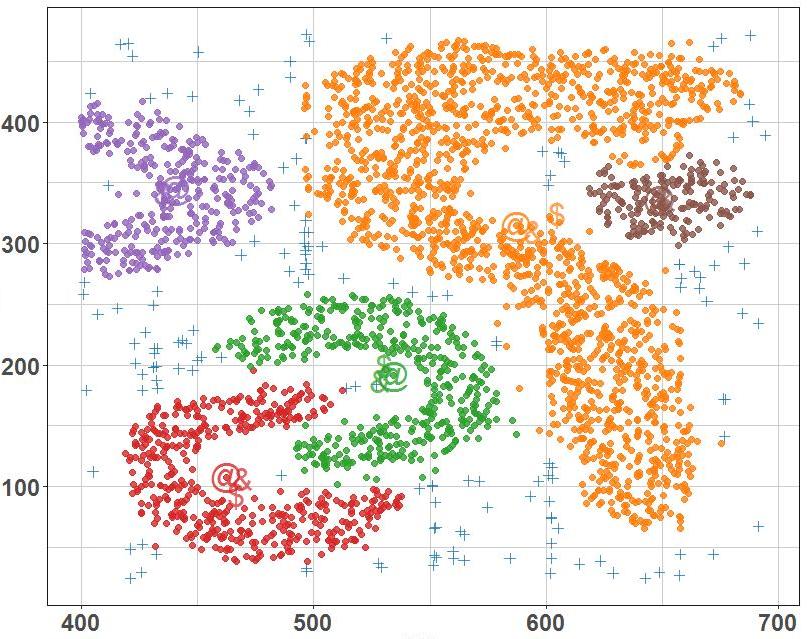
В данном примере группы в основном определяются как области с более высокой непроницаемостью, чем остальная часть набора данных. Объекты в этих редких частях, которые необходимы для разделения всех компонентов, обычно считаются шумом и пограничными точками.
Наиболее популярным методом кластеризации на основе плотности является DBSCAN (алгоритм пространственной кластеризации с присутствием шума). В отличие от многих новых способов он имеет четко определенную кластерную составляющую, называемую «достижимость плотности». Подобно кластеризации на основе связей, она основана на точках соединения в пределах определенных порогов расстояния. Однако такой метод собирает только те пункты, которые удовлетворяют критерию плотности. В исходном варианте, определенном как минимальное количество других объектов в этом радиусе, кластер состоит из всех предметов, связанных плотностью (которые могут образовывать группу произвольной формы, в отличие от многих других методов), а также всех объектов, которые находятся в пределах допустимого диапазона.
Другим интересным свойством DBSCAN является то, что его сложность довольно низкая — он требует линейного количества запросов диапазона к базе данных. А также необычность заключается в том, что он обнаружит, по существу, те же самые результаты (это является детерминированным для основных и шумовых точек, но не для граничных элементов) в каждом прогоне. Поэтому нет никакой необходимости запускать его несколько раз.
 Вам будет интересно:Безбрежный — это... Толкование и синонимы
Вам будет интересно:Безбрежный — это... Толкование и синонимы
Основной недостаток DBSCAN и OPTICS заключается в том, что они ожидают некоторого падения плотности для обнаружения границ кластера. Например, в наборах данных с перекрывающимися распределениями Гаусса — распространенный случай использования искусственных объектов — границы кластеров, создаваемые этими алгоритмами, часто выглядят произвольно. Происходит это, поскольку плотность групп непрерывно уменьшается. А в наборе данных, состоящем из смесей гауссианов, эти алгоритмы почти всегда превосходят такие методы, как EM-кластеризация, которые способны точно моделировать системы такого типа.
Среднее смещение — это кластерный подход, при котором каждый объект перемещается в самую плотную область в окрестности на основе оценки всего ядра. В конце концов, объекты сходятся к локальным максимумам непроницаемости. Подобно кластеризации методом к-средних, эти «аттракторы плотности» могут служить представителями для набора данных. Но среднее смещение может обнаруживать кластеры произвольной формы, аналогичные DBSCAN. Из-за дорогой итеративной процедуры и оценки плотности среднее перемещение обычно медленнее, чем DBSCAN или k-Means. Кроме того, применимость алгоритма типичного сдвига к многомерным данным затруднена из-за неравномерного поведения оценки плотности ядра, что приводит к чрезмерной фрагментации хвостов кластеров.
Оценка
Проверка результатов кластеризации так же сложна, как и сама группировка. Популярные подходы включают «внутреннюю» оценку (где система сводится к одному показателю качества) и, конечно же, «внешнюю» отметку (где кластеризацию сравнивают с существующей классификацией «основополагающей правды»). А ручную оценку эксперта-человека и косвенный балл находят путем изучения полезности кластеризации в предполагаемом приложении.
Внутренние меры отметки страдают от проблемы, заключающейся в том, что они представляют функции, которые сами по себе можно рассматривать как цели кластеризации. Например, можно группировать данные, заданные коэффициентом Силуэт, за исключением того, что не существует известного эффективного алгоритма для этого. Используя такую внутреннюю меру для оценки, лучше сравнивать сходство задач оптимизации.
Внешняя отметка имеет аналогичные проблемы. Если есть такие ярлыки «наземной правды», то не нужно кластеризоваться. И в практических приложениях обычно нет таких понятий. С другой стороны, метки отражают только одно возможное разбиение набора данных, что не означает, что не существует другой (а, может, даже лучше) кластеризации.
Поэтому ни один из этих подходов не может в конечном итоге судить о фактическом качестве. Но это требует человеческой оценки, которая является весьма субъективной. Тем не менее такая статистика может быть информативной при выявлении плохих кластеров. Но не следует сбрасывать со счетов субъективную оценку человека.
Внутренняя отметка
Когда результат кластеризации оценивается на основе данных, которые были сами кластеризованы, это называется данным термином. Эти методы обычно присваивают лучший результат алгоритму, который создает группы с высоким сходством внутри и низким между группами. Одним из недостатков использования внутренних критериев в оценке кластера является то, что высокие отметки необязательно приводят к эффективным приложениям для поиска информации. Кроме того, этот балл смещен в сторону алгоритмов, которые используют ту же модель. Например, кластеризация k-средних естественным образом оптимизирует расстояния до объектов, а внутренний критерий, основанный на нем, вероятно, будет переоценивать результирующую группировку.
Поэтому меры такой оценки лучше всего подходят для того, чтобы получить представление о ситуациях, когда один алгоритм работает лучше, чем другой. Но это не означает, что каждая информация дает более достоверные результаты, чем иная. Срок действия, измеряемый таким индексом, зависит от утверждения о том, что структура существует в наборе данных. Алгоритм, разработанный для некоторых типов, не имеет шансов, если комплект содержит радикально иной состав или если оценка измеряет различные критерий. Например, кластеризация k-средних может найти только выпуклые кластеры, а многие индексы оценки предполагают тот же самый формат. В наборе данных с невыпуклыми моделями нецелесообразно использование k-средних и типичных критериев оценки.
Внешняя оценка
При такой разбалловке результаты кластеризации оцениваются на основе данных, которые не использовались для группировки. То есть таких, как известные метки классов и внешние тесты. Такие вопросы состоят из набора предварительно классифицированных элементов, и они часто создаются экспертами (людьми). Таким образом, эталонные комплекты можно рассматривать как золотой стандарт для оценки. Эти типы методов отметки измеряют, насколько кластеризация близка к заданным эталонным классам. Однако недавно обсуждалось, является ли это адекватным для реальных данных или только для синтетических наборов с фактической истинностью основания. Поскольку классы могут содержать внутреннюю структуру, а имеющиеся атрибуты могут не допускать разделения кластеров. Кроме того, с точки зрения обнаружения знаний, воспроизведение известных фактов необязательно может дать ожидаемый результат. В специальном сценарии ограниченной кластеризации, где метаинформация (например, метки классов) уже используется в процессе группировки, удержание всех сведений для оценочных целей не является тривиальным.
Теперь понятно, что не относится к методам кластеризации, а какие модели применяются для этих целей.